一、项目介绍
《面向北京冬奥会的机器翻译》项目由语言资源高精尖创新中心特聘研究员、清华大学刘洋教授主持开展。项目于2017年立项,2020年11月开展结项工作。该项目面向北京市2022年冬奥会筹办工作的重大需求,对机器翻译展开深入研究,建立了面向冬奥会的机器翻译资源库,探索了基于深度学习的机器翻译理论、模型和算法,研制了支持中文和英文互译的冬奥会机器翻译系统,为《北京冬奥会语言服务行动计划》的跨语言术语服务平台和中心的“语言通”智能服务提供了关键技术支撑。
二、资源库介绍及特点
本项目建设了面向冬奥会的机器翻译资源库,包括:
中文-英文文本机器翻译资源库(112万句对)
中文-英文语音机器翻译资源库(10万句对)
中文-哈萨克文文本机器翻译资源库(10万句对)
中文-哈萨克文语音机器翻译资源库(1万句对)
资源库具备以下特点:
1、资源规模大:中英平行语料库达到112万句对规模,这是目前已知世界上最大的面向冬奥会垂直领域的平行语料库。
2、语种类型多:既包含以中文和英文为代表的资源丰富语言,又包含以哈萨克为代表的资源匮乏语言。
3、领域覆盖全:既包含书面语,又包含口语,能够有力支撑冬奥会场景下正式和非正式场合下的机器翻译业务需求。
4、模态支持好:既包含文本,又包含语音,为研制面向冬奥会的语音机器翻译系统提供了数据基础。
三、冬奥机器翻译系统
(一)文本翻译系统
项目完成中文-英文文本机器翻译系统、中文-哈萨克文机器翻译系统、中文-法文机器翻译系统,在冬奥会数据集上翻译性能超过主流在线翻译系统。
系统目前处于内测阶段,完成后对外提供服务。
(二)语音机器翻译系统
项目针对北京冬奥会的使用场景,采用目前最前沿的深度学习技术搭建了一个移动端的语音翻译系统。系统的前端基于微信小程序开发,后端基于Flask开发。系统可以方便地部署在安卓系统和IOS系统中,只要安装了微信即可使用。

微信扫码体验
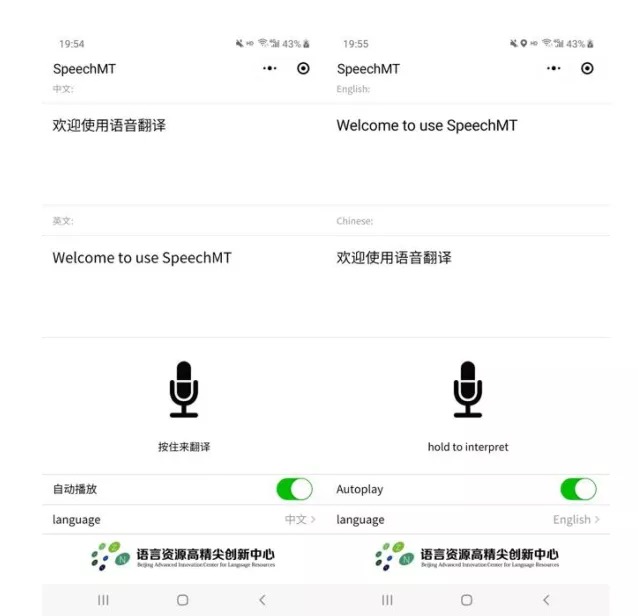
语音翻译小程序截图:中英翻译(左)、英中翻译(右)
上图是微信小程序界面。小程序支持中英、英中两个方向的翻译。用户按住麦克风按钮话,系统将为其返回对应另一种语言的文本和语音。同时系统还会显示语音识别的结果,如果用户发现识别结果有偏差,可以手动更改,系统会自动检测用户修改情况并返回修改后的句子对应的翻译。
三、项目意义
本项目的成果是突破冬奥会语言屏障、实现多语言环境下无障碍沟通的关键技术,不仅与中心的三大工程之一——“语言通” 智能服务密切关联,同时紧扣北京市做好2022年冬奥会筹办工作的重大需求,具有重要的应用价值。项目产生的资源、技术和系统能够为其他面向冬奥会的机器翻译系统与服务提供资源技术和系统上的有力支撑。
项目整体情况介绍视频
